
位置隐私保护是为了防止犯罪分子或不可信的机构在未经用户许可的情况下获得用户的历史位置和当前位置,也是为了防止犯罪分子或不可信的机构根据用户的位置信息和相应的背景知识推断用户的其他个人隐私,如用户的家庭住址、工作场所、工作内容、个人身体状况和生活习惯。以下是一些常用的位置隐私保护技术。
01 基于干扰位置的隐私保护技术
基于干扰的隐私保护技术主要使用虚假信息和冗余信息来干扰攻击者窃取查询用户信息。根据查询用户信息(身份信息和位置信息)的不同,基于干扰的隐私保护技术大致可分为假名技术和假位置技术。
(1)假名技术
假名是基于干扰位置的隐私保护技术中干扰身份信息的技术之一。用户使用假名来隐藏真实的身份信息,比如用户小张的位置(X,Y),在他附近查询KTV,用户小张的查询请求包括:小张,位置(X,Y),“离我最近的KTV”。当攻击者拦截此请求时,用户的所有信息都可以很容易地识别出来。使用假名技术,用户小张使用假名小李,他的查询请求变成:小李,位置(X,Y),“离我最近的KTV”。这样,攻击者就会认为自己在位置(X,Y)人是小李,用户成功地隐藏了自己的真实身份。
假名技术通过向用户分配一个无法跟踪的标志来隐藏用户的真实身份,用户使用该标志代替他们自己的身份信息进行查询。在假名技术中,用户需要有一系列的假名,用户不能长期使用相同的假名,以获得更高的安全性。假名技术通常使用独立的结构和集中的结构,当在独立的结构中使用时,用户只能通过自己的计算和猜测来确定何时何地更换假名,这样两个相同名称的用户可能会同时定位在不同的地方,使服务器和攻击者很容易知道用户使用假名。在集中结构中使用时,用户将更换假名的权利交给匿名服务器,匿名服务器可以通过周围环境和其他用户的信息更好地使用假名。
为了使攻击者无法通过跟踪用户的历史位置信息和生活习惯来将假名与真实用户联系起来,假名也需要以一定的频率定期交换。通常,在使用假名技术时,需要在空间中定义几个混合区域(Mix Zone),用户可以在混合区域交换假名,但不能发送位置信息。
如图1所示,进入混合区前的假名组合是(user1 user2 user3),在混合区域交换假名将产生六种可能的假名组合。由于用户在进入混合区域前后的假名不同,随着进入混合区域的用户数量指数的增加,用户名称为假名的可能性会增加。因此,在混合区域模式下,攻击者很难通过跟踪将用户与假名联系起来,从而达到位置隐私保护的效果。
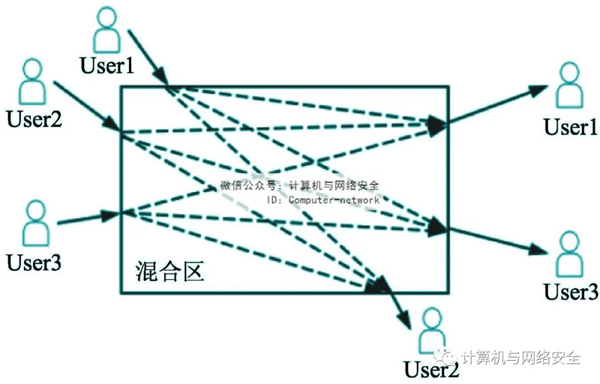
图1 混合区假名交换
混合区域的大小设置和空间部署是假名技术的关键。由于混合区域不需要提交位置信息,混合区域会议会导致服务质量下降,混合区域会议会导致同时区域用户较少,假名交换效率较低。当混合区域只有一个用户时,不会更换假名,从而增加了攻击的可能性。
(2)假位置技术
虚假位置技术是利用虚假位置或添加冗余位置信息来干扰用户在用户提交查询信息时的位置信息。根据位置信息的处理结果,虚假位置技术可分为孤立点虚假位置和地址集。
孤立点假位置是指用户向SP提交当前位置时,不要发送真实位置,而是用真实位置附近的虚假位置代替。例如,用户小张的位置是(X,Y),查询他附近最近离他近的地方KTV,用户小张发送的查询请求不是:小张,位置(X,Y),“离我最近的KTV”,但会使用虚假的位置(M,N)这时,他的查询请求变成了:小张,位置(M,N),“离我最近的KTV”。这样,攻击者就会认为它处于位置(M,N)人是小张,用户小张也成功地隐藏了自己的真实位置。
地址集是通过添加冗余的虚假位置信息形成的,同时发送真实位置。通过干扰攻击者对用户真实位置的判断,将用户的真实位置隐藏在地址集中,以保护用户的位置信息。例如,用户小张的位置是(X,Y),查询附近最近离他的地方。KTV,在用户小张发送的查询请求中,有一个包含真实位置(X,Y)集合取代了用户的位置。因此,他的查询请求变成了:小张,地址集{(X,Y),(X,Y),(X1,Y1),(X2,Y2),(X3,Y3),…},“离我最近的KTV”。这使得攻击者很难从地址中找到用户的真实位置。然而,地址集的选择非常重要。如果地址数量过少,可能无法满足要求的匿名性,而如果地址数量过多,则会增加网络传输的负载。随机生成假位置的算法可以确保在多次查询中生成的假位置具有轨迹性。
(3)哑元位置技术
哑元位置技术也是一种假位置技术,也可以通过添加假位置来实现k-匿名。在查询过程中,除真实位置外,还需要添加多个假位置信息。服务器不仅响应真实位置的要求,还响应假位置的要求,使攻击者无法区分用户的真实位置。
假设用户的初始查询信息为(user_id locreal),locreal使用假位置技术后,用户的查询信息将成为用户的当前位置q*=(user_id,locreal,dummy_loc1,dummy_loc2),其中dummy_loc1和dummy_loc2假位置。
哑元位置技术的关键在于如何生成无法区分的假位置信息。如果假位置出现在湖泊或人烟稀少的山区,攻击者可以排除它。假位置可以直接由客户生成(但客户通常缺乏全球环境等信息),也可以由可信的第三方服务器生成。
02 基于泛化位置隐私保护技术
泛化技术是指将用户的位置模糊成包含用户位置的区域。基于泛化位置最常用的隐私保护技术是k-匿名技术。k-匿名是指在泛化区域,包括查询用户等k-1个用户。SP区域内其他用户的位置无法区分查询用户的位置。因此,匿名区域的形成是决定k-集中结构和匿名技术的重要因素P2P结构来实现。
k-匿名技术要求发布的数据包括k不可分割的标志符使特定个体被发现的概率为1/k。在位置隐私保护中,k-匿名通常需要生成一组k用户查询集,然后用户可以使用由查询集组成的共同匿名区域。图2显示用户User1、User2和User3匿名区域((Xl,Yl),(Xr,Yr))。
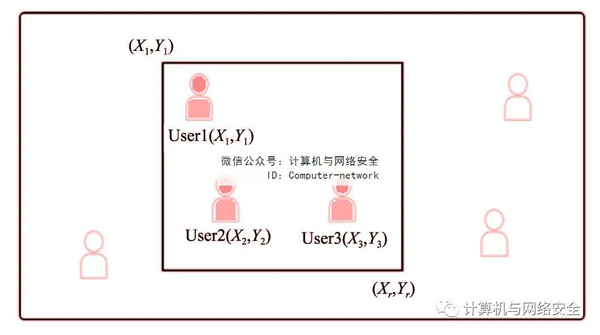
图2 混合区假名交换
k-匿名技术中通常要求的参数如下。
① 匿名度k:定义匿名集中的用户数量。k位置隐私了位置隐私保护的程度,更大k值意味着匿名集包含更多的用户,这使得攻击者更难区分。
② 最小匿名区域Amin:定义要求k用户位置组成空间的最小值。当用户分布密集时,匿名区域太小。即使攻击者无法准确区分匿名用户,匿名区域也可能向攻击者暴露用户的位置。
③ 最大延迟时间Tmax:定义用户可接受的匿名等待时间最长。
k-匿名技术在某些情况下仍然可能暴露用户的隐私信息。例如,当匿名集中用户的位置经纬度信息可以映射到特定的物理场所(如医院)时。为此,增强l-多样性、t-closeness当技术被提出时,匿名集中用户的位置必须相距足够远,以免在同一物理场所。
k-匿名技术可以通过匿名服务器收集和查询匿名收集,也可以通过分布式点对点技术由多个客户组成。
(1)集中式k-匿名
典型的集中式k-匿名是间隔匿名。间隔匿名算法的基本思想是:匿名服务器构建四叉树的数据结构,将平面空间交叉分为四个相同面积的正方形区间,直到最小正方形区间的面积是允许用户使用的最小匿名区域,每个正方形区间对应四叉树中的一个节点。系统中的用户每隔一段时间向匿名服务器报告一次位置坐标,更新并统计每个节点对应范围内的用户数量。U匿名查询时,匿名器会为用户检索四叉树U生成一个匿名区ASR,间隔匿名算法包括用户U四叉树的叶节点开始向四叉树根的方向搜索,直到它被发现不少于K用户(包括用户)U)节点,然后将节点对应的区域作为用户U匿名区。如图3所示,如果用户U1发起K=2对于匿名查询,间隔匿名算法将首先搜索象限范围[(0、0)、(4、4)],其中包含不少于两个用户,然后将一级搜索到象限范围[(0、0),(2,2)】象限区间包含3个用户,超过两个要求,算法停止搜索,并将该区间作为用户U1匿名区域。该算法获得的匿名区域的用户数量可能远远大于K,所以它会增加LBS查询处理负荷和网络流量负荷的服务器。
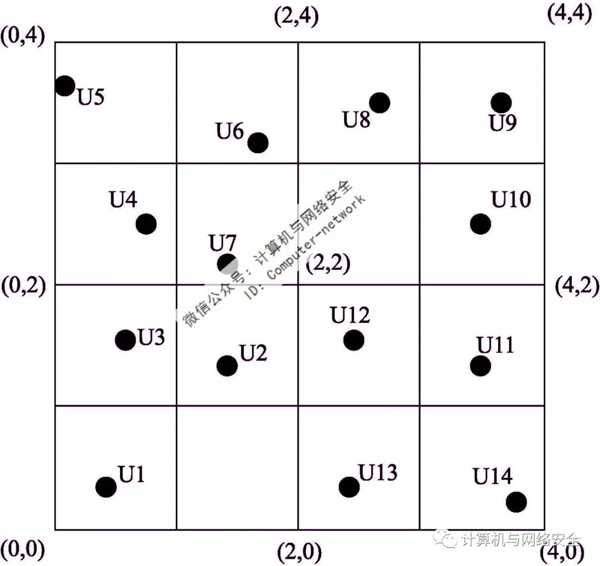
图3 k-匿名实例
Casper匿名算法类似于间隔匿名算法,但与间隔匿名算法不同的是:Casper采用Hash当搜索节点的用户数小于四叉树的叶节点时,表示识别和访问四叉树的叶节点K当时,首先搜索相邻的两个兄弟节点。如果该节点与相邻的两个兄弟节点合并后的总用户数大于K,将它们合并并为匿名区域,否则将搜索其父节点。Casper生成的匿名区面积相比于间隔匿名算法生成的要小,这会减少网络的负载。
Hilbert匿名算法的基本思想是通过Hilbert空间填充曲线将用户的二维坐标位置转换为一维Hilbert匿名值,按曲线通过的顺序编号用户,即用户Hilbert相邻的k一个用户放在同一个桶里。匿名集是包含请求服务的用户所在桶中的所有用户。计算匿名集的最小绑定矩形,并将其用作匿名区域。如果两个用户相邻于二维空间,则映射到一维空间Hilbert相邻的概率也很大。Hilbert匿名算法可以满足绝对匿名。如图4所示,用户U1匿名度为3,他和他的邻居U3和U4共同组成了匿名区域。
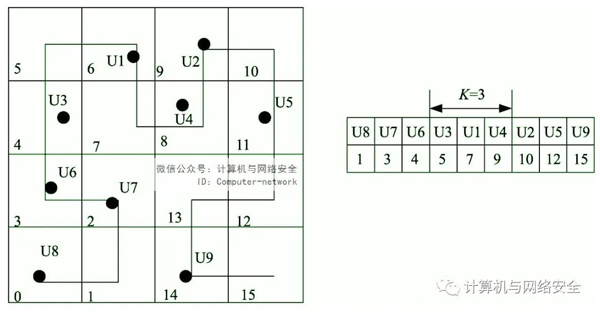
图4 Hilbert匿名实例
(2)P2P结构下的k-匿名
基于P2P结构的k-匿名查询算法的基本思想是假设所有节点都是可信的。每个用户都有两个独立的无线网络,一个用于与LBS另一个网络用于通信P2P通信,系统中的用户安全可信。完整的查询过程包括以下三个步骤。
① 等点查询。移动用户需要通过单跳或多跳网络搜索不少于。k-1对等邻居。
② 生成匿名区。移动用户和他发现的k-1一个邻居形成一个小组,准确地隐藏在覆盖整个小组所有用户的区域(即匿名区域)中。如果生成ASR面积小于用户要求的最小匿名区Amin,那么就需要扩大这个匿名区ASR最小匿名面积Amin。
③ 选择代理并查询。为了防止攻击者通过移动蜂窝定位技术攻击,移动用户需要在组中随机找到平等的邻居作为代理。特别用于P2P通信网络通过另一个网络告知代理生成的匿名区域和查询参数LBS联系服务器,发送查询参数和匿名区域,接收候选集,然后代理专门用于P2P的网络将候选集传回查询用户。最后查询用户对返回的候选集进行过滤,得到查询结果。
03 基于模糊法的位置隐私保护技术
位置混淆技术的核心思想在于通过降低位置精度来提高隐私保护程度。一种模糊法可将坐标替换为语义位置,即利用带有语义的地标或者参照物代替基于坐标的位置信息,实现模糊化。也有用圆形区域代替用户真实位置的模糊法技术,此时,将用户的初始位置本身视为一个圆形区域(而不是坐标点),并提出3种模糊方法:放大、平移和缩小。利用这3种方法中的一种或两种的组合,可生成一个满足用户隐私度量的圆形区域。
例如,包括用户位置的经纬度坐标在内的圆形或矩形区域可以作为用户位置提交。当提交查询时,我们使用圆形区域C1替换用户的真实位置(X,Y)。
此外,还可以使用基于物理场所语义的混淆技术,它将提交用户的位置,而不是用户的具体坐标。例如,在西安交通大学校园使用的语义位置“图书馆”替换我的具体坐标;也可以使用“兴庆公园”用户黑点位置显示用户,启动查询“最近加油站”定位服务。
混淆技术的关键是如何产生混淆空间。用户总是处于混淆区域的中间,或者混淆区域的大部分区域是用户无法到达的河流,或者混淆区域的人口相对稀疏,这将增加攻击者找到用户真实位置的可能性。
大多数模糊技术可以直接在用户端实现,而无需额外的信息辅助,因此它们主要使用独立的结构。
与泛化法不同,大多数模糊法技术没有能力对付它LBS处理返回结果往往会产生粗糙度LBS结果如图5中兴庆公园模糊用户请求“最近加油站”时,事实上S1是最近的加油站,当将C1作为其模糊区域,可以找到正确的结果;但当隐私程度较高时C2作为模糊区,SP将把S2作为结果返回。所以,虽然C2的半径大于C1这提高了隐私程度,但此时SP没有最好的满足用户需求。如何解决模糊技术?“保证LBS服务质量”和“满足用户隐私需求”寻求平衡。解决这个问题的一种方法是SP采用迭代询问的方法,不断征求用户是否同意降低其隐私度并尽可能提高服务质量。
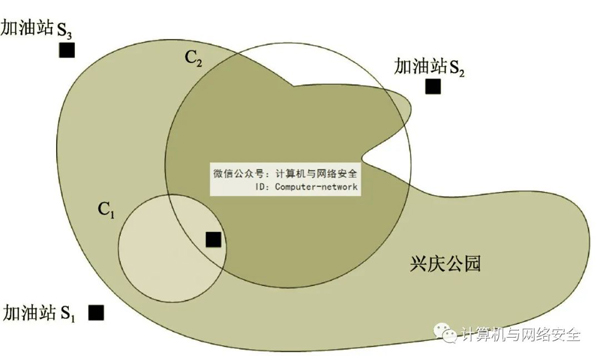
图5 基于模糊法的隐私保护技术
04 基于加密位置的隐私保护技术
在基于位置的服务中,用户的位置和兴趣点在基于加密位置的隐私保护技术加密后,会在密文空间中检索或计算,SP无法获得用户的位置和查询的具体内容。基于隐私信息检索的两种典型隐私保护技术(Private Information Retrieval,PIR)基于同态加密的位置隐私保护技术和位置隐私保护技术。
(1)基于隐私信息检索(PIR)位置隐私保护技术
PIR是客户端与服务器通信的安全协议,可以确保客户端在向服务器发起数据库查询时完成查询,并返回查询结果。例如,服务器S拥有不可信赖的数据库DB,用户U要查询数据库DB[i]中的内容,PIR用户可以通过高效的通信获得DB[i],同时,服务器服务器知道i的值。
在基于PIR在位置隐私保护技术中,服务器无法知道移动用户的位置和要查询的具体对象,从而防止服务器根据用户查询的对象获取用户的位置信息,确定用户的兴趣点,推断用户的隐私信息。其加密理念如图6所示:用户希望获得SP位于服务器数据库中i内容,用户自己加密查询请求Q(i),并发送给它SP,SP在不知道i找到X,加密结果R(X,Q(i))并返回给用户,用户可以轻松计算Xi。包括SP包括攻击者在内的攻击者无法通过分析获得i,因此,无法获得查询用户的位置信息和查询内容。
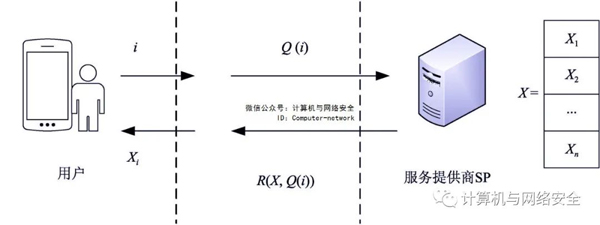
图6 PIR方案
PIR确保用户请求、信息检索和结果返回安全可靠。PIR要求SP存储整个区域的兴趣点和地图信息,极大地挑战了存储空间和检索效率。如何设计更合适的存储结构和检索方法PIR继续研究的重点。
(2)基于同态加密位置的隐私保护技术
同态加密是一种支持密文计算的加密技术。对同态加密后的数据进行计算等处理,处理的过程不会泄露任何原始内容,处理后的数据用密钥进行解密,得到的结果与没有进行加密时的处理结果相同。基于同态加密的位置隐私保护最常用的场景是邻近用户相对距离的计算,它能够实现在不知道双方确切位置的情况下,计算出双方间的距离,如微信的“摇一摇”功能。Paillier同态加密是基于加密隐私保护技术常用的同态加密算法,是最典型的Louis协议和Lester协议。Louis协议允许用户A与用户计算B的距离,Lester协议规定只有当用户A和用户B用户之间的距离B只有在设置范围内,用户才能被允许A计算两者之间的距离。
05 位置隐私攻击模型
网络中的攻击者是用户位置隐私的最大威胁来源。攻击者形成了不同位置隐私保护技术的攻击模型。这些攻击模型可分为主动攻击模型和被动攻击模型。
1. 主动攻击模型
攻击者或受害者LBS为了获取用户的位置信息或干扰用户的使用,服务器发送恶意信息LBS服务。主要包括伪装用户攻击和信息洪水攻击。
(1)伪装用户攻击
主要基于伪装用户攻击P2P结构的位置隐私保护技术。在P2P在结构下,同一网络中的用户相互信任。攻击者可以假装是用户的朋友或其他普通用户,或者将病毒植入网络中用户的移动设备中来控制这些设备。此时,攻击者将主动向受害者用户申请协助定位。由于受害者的信任,攻击者可以很容易地获得用户的准确位置信息。
伪装用户攻击对基于同态加密的位置隐私保护技术也有很好的攻击效果。当攻击者在受害者设置的限定范围内获得受害者用户的信任或距离时,攻击者可以计算出他与受害者之间的相对距离。根据三角定位原则,当攻击者成功获得三个或三个以上的相对距离时,通过简单的计算可以知道受害者用户的准确位置。
在现有的位置隐私保护算法中,伪装用户攻击还没有很好的解决办法。
(2)信息洪水攻击
信息洪水攻击的原则是拒绝服务。在独立和集中的结构中,攻击者向LBS大量服务器发送LBS请求,占用LBS影响服务器带宽和流量的服务器LBS服务器对受害者的服务效率。P2P在结构中,攻击者可以直接向受害者发送大量的协助定位应用程序,因为用户可以在结构中发送协助定位应用程序。这些应用程序将像洪水一样涌向受害者。受害者不仅需要接受这些信息,还需要处理和转发这些信息。大量的信息会导致受害者的移动网络堵塞,甚至移动设备崩溃。
2. 被动攻击模型
被动攻击是指攻击者被动地收集受害者的信息,并通过收集到的信息推断用户的真实位置。被动攻击主要包括基于历史信息、语义信息和社会关系的攻击。
(1)基于历史信息的攻击
基于历史信息的攻击主要通过收集受害者相关的历史信息来分析用户LBS使用习惯来推测用户的具体位置。历史信息包括受害者之前发起的LBS请求的时间、内容、频率等。例如,如果受害者经常在晚上或周末使用导航到同一个地方,那么这个地方很可能是受害者的家庭地址。同样,如果受害者经常在工作日查询某个地方附近的餐厅,那么这个地方很可能是用户的工作地点。
(2)基于语义信息的攻击
基于语义信息的攻击者可以通过分析受害者所在区域的信息和周围环境的语义信息来缩小用户所在区域的范围,增加识别用户位置的可能性。例如,攻击者截获了受害者所在区域的信息,发现该区域包括一个人工湖、几栋高层建筑和一个停车场。可以推断,用户位于湖中的概率远低于建筑物和停车场的概率。如果你知道用户正在使用导航功能来找到去某个地方的路线,那么用户位于停车场的概率高于建筑物的概率。
(3)基于社会关系的攻击
基于社会关系的攻击主要利用当今发达的社交网络。首先,攻击者收集受害者的社交信息,通过攻击其他社交网络中的用户来间接攻击受害者。如果用户A非常重视他们的位置隐私保护,攻击者很难直接攻击用户A,通过社交网络,用户A和用户B是同事,攻击者可以攻击用户B,通过获取用户B的工作地点来推断用户A的工作地点。