
轨迹隐私是一种特殊的个人隐私,是指用户运行轨迹本身包含的敏感信息(如用户去过的一些敏感区域等),或其他个人信息(如用户的家庭住址、工作地点、健康状况、生活习惯等)。因此,轨迹隐私保护不仅要确保轨迹本身的敏感信息不泄露,而且要防止攻击者通过轨迹推导其他个人信息。
01 轨迹隐私测量
在轨迹数据发布过程中,为了方便研究人员的研究和使用,发布的数据在隐私保护中需要具有较高的数据可用性。对于位置隐私保护,保护技术不仅要保护用户的隐私安全,还要确保用户能够享受更高的服务质量。
对于轨道隐私的保护程度,一般可以用三个指标来衡量:轨道上点与点之间的相关性、轨道中数据点的准确性和轨道隐私泄露的可能性。
轨迹是指用户在一天内的位置和时间相关排序的一组序列。轨迹可以表示为Ti={(xi1,yi1,ti1),(xi2,yi2,t2i),…,(xji,yji,tji),…,(xni,yni,tni)}。其中,Ti表示第i用户的轨迹,(xji,yji,tji)(1≤j≤n)表示此移动的用户在tj时刻的位置是(xji,yji),tj为采样时间。基站或服务器在一天内收集用户的所有数据,然后根据时间将位置数据串联起来。轨迹数据富含时空信息,分析和挖掘轨迹可以支持许多移动应用。例如,研究人员可以通过分析人们的日常轨迹来研究人类的行为模式;政府机构可以使用用户的移动GPS轨道数据可以分析基础交通设施的建设。可以看出,用户的轨道数据为社会发展提供了大量信息,也会带来隐私和安全问题。
轨迹隐私和位置隐私之间最大的区别在于轨道包含时间和位置的相关信息,其他信息很容易通过一个信息推断出来。在传统的轨道隐私测量方法中,大多使用时间和空间进行分析和测量,然后添加轨道形状来测量轨道,可以更准确地测量两个轨道之间的相似性。
在定义轨迹相似性的测量标准时,需要从两个方面来考虑。如图1所示,有三个轨迹,每个轨迹有五个数据点,每个数据点在同一采样时间采样,假设每个采样时间的三个数据点x只有轴坐标相同y轴坐标不同。通过计算相应数据点之间的欧氏度距离,最终得出轨迹2和轨迹3到轨迹1的距离相等。但从图中可以看出,轨迹2与轨迹1的形状完全相同,而轨迹3与轨迹1不同,因此轨迹2与轨迹1的相似性明显强于轨迹3与轨迹1的相似性。因此,在测量轨迹相似性时,应从两个方面入手。
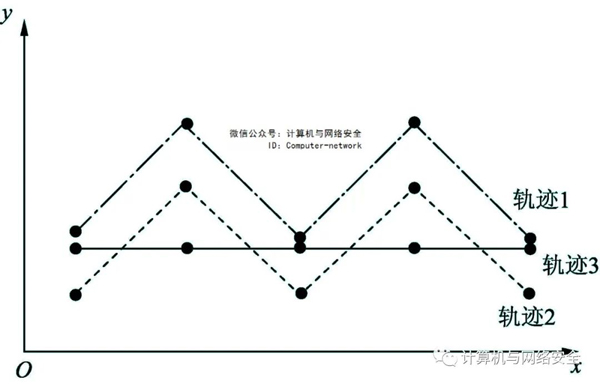
图1 轨迹相似性对比
轨迹形状距离:给定两条轨迹Ti={(x1i,y1i,t1i),(xi2,y2i,t2i),…,(xni,yni,tni)}和Tj={(x1j,y1j,t1j),(x2j,y2j,t2j),…,(xnj,ynj,tnj)},两条轨示:
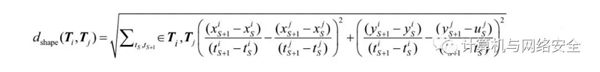
轨道位置距离:定义6.1两条轨道之间的位置距离如下:
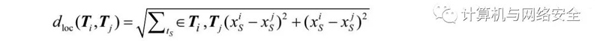
根据上述两种距离形式的定义,加权合并可以获得两个轨迹的轨迹距离。
轨距:轨距定义如下:
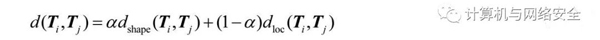
这里,α∈[0,1]是轨迹形状距离和轨迹位置距离的权重,一般值为α=0.5。
02 轨道隐私保护场景
目前,关于轨迹隐私保护的研究工作主要解决下述两种应用场景中的隐私问题。
1. 数据发布中的轨迹隐私保护
轨迹数据本身包含丰富的时间和空间信息,轨迹数据的分析和挖掘结果可以支持各种移动应用程序。因此,许多政府和研究机构都加强了对轨迹数据的研究。例如,美国政府使用移动用户GPS轨迹数据分析基础交通设施的建设,为是否更新和优化交通设施提供依据;社会学研究者通过分析人们的日常轨迹来研究人类的行为模式;一些公司通过分析员工的工作轨迹来提高员工的工作效率。然而,如果恶意攻击者在未经授权的情况下计算和推理其他与轨迹相关的个人信息,用户的个人隐私将通过轨迹完全暴露。数据发布中的轨迹隐私泄露大致可分为以下两类。
① 轨道上敏感或频繁访问位置的泄露导致移动对象的隐私泄露。轨道上敏感或频繁访问的位置可能会暴露其个人隐私,如个人兴趣、健康状况和政治倾向。例如,如果一个人在一定时间内频繁访问医院或诊所,攻击者可以推断该人最近患有某种疾病。
② 移动对象的轨迹与外部知识的关系导致隐私泄露。例如,有人每天早上在固定的时间段从地点出发A出发到地点B,每天下午在固定的时间段从地点出发B出发到地点A,通过挖掘分析,攻击者很容易做出判断:A是某人的家庭住址,B它的工作单位。通过搜索A所在区域和B该地区的邮政编辑、电话簿和其他公共内容很容易确定一个人的身份、姓名、工作地点、家庭住址和其他信息。因此,某人的个人隐私通过其操作轨迹被完全泄露。
在轨迹数据发布中,最简单的隐私保护方法是删除每个轨迹的标志属性,即QI属性。然而,简单地说,它将是QI移除属性并不能保护移动对象的轨迹隐私。攻击者还可以通过匹配背景知识(如受攻击者的博客、对话记录或其他外部信息)来推导个人隐私信息。
例如,在删除了QI在属性数据中,攻击者在某个时刻发现了移动对象ti访问了地点L1和L2,小王一直在攻击者已知的背景知识中ti如果小王在左右分别访问这两个位置,ti唯一分别访问的时刻L1和L2对于移动对象,攻击者可以确定轨迹属于小王,然后从轨迹中找到小王访问的其他位置。可以看出,移动对象的简单删除QI属性不能保护隐私。
2. 位置服务中轨道隐私保护
用户在获取LBS服务时,需要提供自己的位置信息。为了保护移动对象的位置隐私,有位置隐私保护技术。然而,保护移动对象的位置隐私并不意味着它可以保护移动对象的实时运行轨迹隐私。攻击者很可能通过其他方式获得移动对象的实时运行轨迹。例如,使用位置k-当匿名模型保护发出连续查询的用户的位置隐私时,移动对象匿名框的位置和大小将不断更新。如果发送移动对象LBS当请求连接到匿名框时,您可以得到移动对象的一般运行路线。这是因为移动对象在查询过程中生成的匿名框包含了不同移动对象的信息,仅仅延长匿名框的有效时间就会导致服务质量的下降。虽然存在连续查询位置隐私保护技术,但查询有效期为秒,不能满足轨迹隐私保护的需要。因此,在LBS轨迹隐私保护技术也需要。
轨迹隐私保护需要解决以下两个关键问题:
① 保护轨道上的敏感性/不泄露频繁访问位置的信息;
② 保护个体与轨迹之间的关系不泄露,即确保个体不能与轨迹匹配;
③ 防止因最大速度、路网等相关参数而泄露移动对象轨迹隐私的问题。
03 轨道隐私保护技术分类
轨迹隐私保护技术大致可分为三类。
(1)基于假数据的轨迹隐私保护技术
该技术通过添加假轨迹来干扰原始数据,并确保干扰轨迹数据的一些统计属性不会严重扭曲。基于虚假数据的轨迹隐私保护技术主要是在原始数据的基础上添加虚假数据,然后干扰原始轨迹数据,不会扭曲原始轨迹数据。例如,表1中有三个移动对象O1、O2、O3,表中的数据分别对应于它们t1、t2、t3在数据点中,每个对象可以根据时间关联形成轨迹。

表1 原始数据
用假数据法干扰表1中的数据后,形成了6条轨迹,如表2所示,在这6条轨迹中,I1、I2、I3是O1、O2、O3假名。因此,每个真实轨迹被泄露的风险可以降低到0.5。
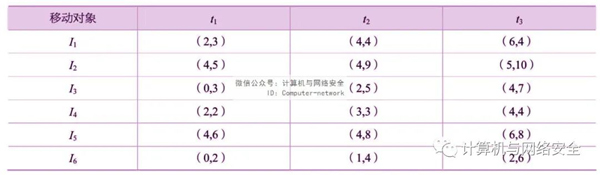
表2 用假数据法干扰的数据
对于虚假数据方法,虚假轨迹的数量越多,泄露的风险就越低,但这将对原始数据产生更大的影响。虚假轨迹的产生增加了空间关系的复杂性,并产生了许多交叉点,可以降低风险,因为它很容易混淆。在运行模式中,虚假轨迹的运行模式与原始轨迹相似,也会对攻击者的攻击产生一定的影响。这种方法简单,计算量小,但容易扩大存储容量,降低数据可用性。
(2)基于泛化法的轨迹隐私保护技术
该技术是指将轨道上的所有采样点泛化为相应的匿名区域,以实现隐私保护的目的。基于泛化法的轨迹隐私保护技术泛化了轨迹中的所有点,并将其泛化为数据点对应的匿名区域,以实现隐私保护的目的。在泛化保护技术中,最常用的是轨迹k-匿名保护技术的主要保护技术是泛化其需要保护的核心属性,使其无法与其他技术一起使用k-1条记录区分开来。对于表1中的轨迹数据,将其中三个轨迹泛化匿名,即将数据点泛化为匿名区域,如表3所示。

表3 轨迹6-匿名
在进行匿名时依然通过假名进行发布,同时也须对3个匿名时刻中的数据点进行匿名泛化。此方法可以保证数据是真实数据,但由于计算费用较大,需要考虑性能。
(3)基于抑制法的轨迹隐私保护技术
该技术根据具体情况有条件地发布轨迹数据,不发布轨迹上的一些敏感位置或频繁访问位置,以实现隐私保护。表4显示了表2抑制发布后的数据。

表4 抑制方法轨迹匿名
与其他方法相比,抑制方法简单有效,轨迹保护也可以在攻击者具有一定背景知识的前提下进行,效率相对较高。但当不能准确理解攻击者的背景知识时,该方法就不再适用了。另一方面,该方法限制了敏感数据的发布和简单的实现过程,但信息丢失太大。
简而言之,基于虚假数据的轨迹隐私保护技术简单,计算量小,但容易导致虚假数据存储量大,数据可用性降低;基于泛化法的轨迹隐私保护技术可以保证数据的真实性,但计算成本大;基于抑制法的轨迹隐私保护技术可以限制发布一些敏感数据,但信息丢失量大。目前,基于泛化法的轨迹k-匿名技术在隐私保护度和数据可用性上取得了较好的平衡,是目前轨迹隐私保护使用的主流方法。
04 基于语义的轨迹隐私保护方法
原始轨迹数据与用户的各种隐私信息密切相关。如果不发布收集到的轨迹数据,恶意攻击者可以挖掘和分析轨迹数据,获得用户的家庭地址、兴趣、行为模式等敏感信息。因此,必须遵循离线轨迹数据的发布“数据采集、隐私保护处理、轨迹发布”的原则。
轨迹发布后,商业机构和科研机构都希望从保护轨迹中分析可用的信息。因此,轨迹隐私保护处理的目标是防止恶意攻击者从处理轨迹中猜测用户的敏感信息,并确保处理轨迹仍具有较高的完整性和数据可用性。
目前,离线轨迹发布中的隐私保护方法,如轨迹聚类、虚假轨迹等,只将轨迹数据视为欧洲空间中具有时间属性的位置点序列,只考虑轨道的时间和空间属性,而忽略了实际环境中每个采样点的位置信息,即轨道的语义属性。
一般来说,用户轨迹上的位置点可以分为移动点和停留点。移动点只能分析用户通过的道路,但停留点可以反映用户在一定时间内的重要位置特征。通过分析停留点,我们可以知道用户经常访问的位置,然后推断用户的工作地址、兴趣甚至宗教信仰、身体状况和其他私人信息。因此,停留点将比移动点暴露用户更敏感的信息。保护停留点不仅可以确保用户的隐私,而且可以减少对原始轨迹的损害,并在隐私保护和数据可用性之间取得良好的平衡。
在现实生活中,不同的用户同一语义位置的敏感性可能不同。例如,患者和医生对医院的敏感性不同,患者可能不想暴露自己的健康状况,但医生通常不介意他们的工作场所被泄露。因此,在保护轨迹时,用户的个性化隐私需求不容忽视。如果所有用户都采用相同的处理标准,可能会导致一些用户的轨迹保护不足和隐私泄露,一些用户的轨迹保护过度,导致数据损失。
忽略轨迹的语义属性会导致一些现有的解决方案容易受到语义攻击。用户更关心他们经常访问和停留的地方是否会泄露隐私,而不是他们经过的地方。因此,为了保持轨道的最大完整性,没有必要保护轨道上的所有取样点。
图2提出的方案旨在保持轨道安全与数据可用性之间的良好平衡,用停留点周围不同语义的兴趣点取代敏感停留点,重置少量采样点以隐藏用户的敏感信息。该方案采用个性化的隐私保护,用户可以定制自己的敏感语义位置集和隐私保护程度,以确保轨道隐私的安全,确保轨道不过度处理。
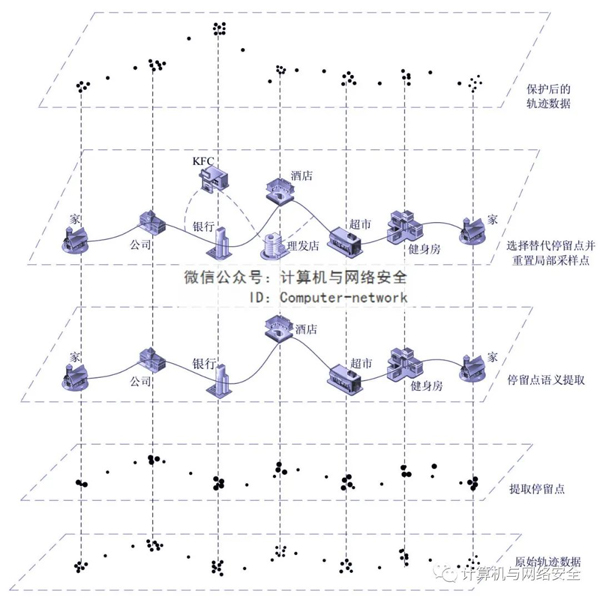
图2 基于语义的轨迹隐私保护方案示意
1. 基于语义的轨迹隐私保护方案
该方案首先根据原始轨迹数据分析用户的移动特征,对时间、经度和纬度进行多维聚类,提取用户一天内的停留点集合,利用地图反分析获取停留点对应的实际位置,并标记其语义;其次,根据用户自定义的敏感语义位置集,获取用户的敏感停留点集合(即图2中的银行和酒店);然后,结合用户的移动方向,合理规划每个敏感停留点的候选区域,分析候选区域兴趣点的语义和距离特征,找到满足用户隐私需求的不同语义的兴趣点,将包含这些兴趣点的最小矩形作为敏感区域,并在敏感区域随机选择替代停留点(即图2中KFC和理发店);最后,为了防止更换停留点导致轨道位置突变,减少轨道变化,只重新选择敏感区域的局部取样位置点,确保敏感区域的取样位置点数量与原始轨道一致,形成最终可发布的轨道数据。
2. 提取语义停留点
本方案的首要任务是根据用户轨迹提取语义停留点。
用户在日常生活中会产生大量的停留点:对于大多数用户来说,从晚上12点到早上6点,用户的家庭位置成为他的停留点;用户的日常工作场所也将成为他的停留点;银行也将成为银行业务用户的停留点。
对于具有地图背景知识的恶意攻击者,通过提取用户轨迹中的停留点并将其映射到语义地图上,用户可以获得大量的个人隐私。
用户轨迹上的所有取样点都具有相应的语义属性。恶意攻击者对用户频繁访问和长时间停留的位置点更感兴趣,因为他们可以挖掘和分析更多的用户隐私信息。因此,保护停留点的隐私至关重要。
图3显示了用户在一段时间内的轨迹数据Traj={P1,P2,…,P9}。通过分析可以看出,轨迹中的5个连续采样点{P3,P4,P5,P6,P7}它们都在一定的范围内,从而推断用户已经停留在这个地方(图中的虚线圈)。具有地图背景知识的恶意攻击者可以将停留点映射到真实地图中,获取用户停留的地点,并获取用户的一些隐私信息。
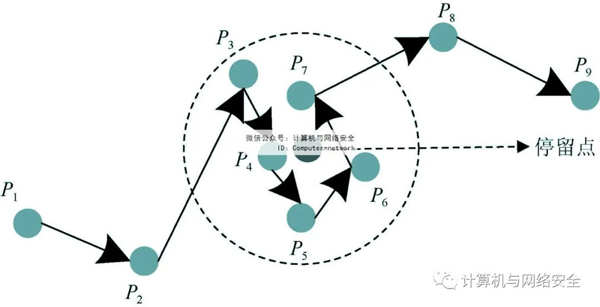
图3
从上面的例子中不难看出,有背景知识的攻击者通过挖掘和分析用户停留点,可以轻松获得大量用户隐私信息。保护敏感停留点不需要处理轨道上所有的采样位置点,既能隐藏轨道上用户的敏感信息,又能减少对原始轨道的破坏。
该方法首先读取一段时间内所有用户的原始轨迹数据,如图4所示,Lij表示用户Mi(1≤i≤m)在tj(1≤j≤n)在时间位置,对每个用户的轨迹进行多维聚类,包括时间、经度和纬度聚类,以提取用户的个人停留点集合。聚类需要三个阈值:时间阈值σt、距离阈值σd位置点数阈值σn。

图4
然后,通过在用户轨迹上的采样位置点,可以找到所有的停留核心点。停留核心点是用户Mi在tj时间点Lij,遍历用户轨迹上的所有位置点Lik(1≤k≤n)与之比较,找到所有的满足感|Lij-Lik|≤σd且|tj-tk|≤σt的点。如果Lij处满足以上条件的点的数量不少于σn,则Lij留在核心点。
最后,将时空相邻的停留核心点划分为一个集合,最终获得多个停留核心点的集合,称为语义停留点。
由此可见,通过多维聚类分析个人用户的多维空间数据,可以获得用户的移动特征;根据用户的移动特征,可以提取个人停留点集合;通过标记其语义,根据用户自定义的敏感语义位置,将停留点映射到地图上,获得个人敏感停留点集合(即语义停留点集合)。
3. 合并语义停留点
由于某种原因,采样位置点与前后相邻时间的采样位置点之间的距离可能过大,如图5所示。P5与P4和P6两者之间的距离太大,不符合现实,即采样时间内无法到达采样位置点及其相邻位置点。异常点的存在会影响个人停留点的提取和语义标记的准确性。因此,在将相邻的停留核心点集成到停留点之前,需要扫描轨迹数据以检测异常点。正常用户的行走速度约为3 km/h,当用户停留在某个地方时,他们通常处于静止或缓慢移动的状态。速度不应大于正常移动速度。可根据采样时间计算距离δ,如果tj始终采样位置Lij采样位置点与前后相邻时间的距离差|Lij-Li(j-1)|和|Lij-Li(j 1)|均大于δ,则认为Lij采样异常点,合并相邻核心点时应放弃异常点。轨迹数据检测和异常点放弃后,可合并停留核心点。
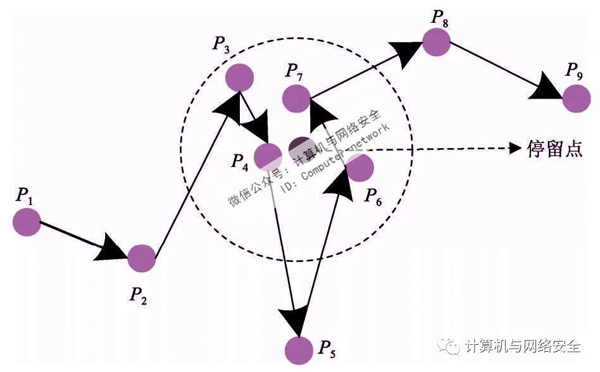
图5 采样异常点
通过上述方法,每个用户可以在一段时间内收集停留点SP={SP1,SP2,…,SPn},其中SPi(1≤i≤n)是多个停留核心点的停留点,每个停留点中包含的停留核心点可以表示为SPi={P1,P2,…,Pm}。后续需要更换停留点和重置采样点,这里可以覆盖SPi作为停留点的代表坐标,所有停留核心点的最小覆盖圆中心,如图所示。5中的停留点需要最小覆盖圆半径,以便后续重置采样点。
每个停留点SPi={P1,P2,…,Pm},最小覆盖圆的基本思想是:首先SPi内任选择三个停留核心点形成三角形,找出三角形的最小覆盖圆中心和半径;然后通过剩余的停留核心点,判断该点是否在已得到的圆中。如果在圆中,则表示圆仍然是最小的覆盖圆。如果不在圆中,则在上述三点中随机选择两个点与该点形成新的三角形,并重新计算新的最小覆盖圆的中心和半径。重复上述过程,直到找到能够覆盖所有停留核心点的最小覆盖圆的中心和半径。
每个停留点的坐标信息和覆盖范围可以通过上述方法获得。然后调用百度地图Web服务API,使用逆地址编码服务,获取停留点坐标的位置,并标记其语义属性。
4.替换敏感停留点strong>
提取用户原始轨迹上所有敏感停留点后,敏感停留点必须根据用户个性化隐私保护程度的要求,在合理的空间范围内用不同语义的兴趣点取代。其中,选择合适的替代停留点是关键。为了保证处理后轨迹的安全性和完整性,替代停留点的选择不能完全随机,需要充分考虑用户的移动方向、兴趣点的语义、距离等特点。替代停留点的选择过程分为两部分:首先为每个敏感停留点建立合适的候选区域,然后在候选区域选择合适的兴趣点作为替代停留点。
(1)建设候选区
为防止替代停留点偏离相应的敏感停留点太远,影响保护后轨迹数据的可用性,应根据敏感停留点建立候选区域。候选区域的范围由敏感停留点和轨道上与时空相邻的前后两个停留点之间的距离决定。
如图6所示,用户轨迹上有敏感的停留点SP2和SP3。如果在候选区的重叠区域选择自己的替代停留点SP′2和SP′3,通过比较发现,保护轨迹在形状和方向上与原始轨迹有很大的偏差,严重降低了两条轨迹之间的相似性。由于保护轨迹与原始轨迹之间的相似性是衡量轨迹数据可用性的重要指标,为了防止更换敏感停留点会破坏轨迹的可用性,有必要确保相邻敏感停留点的候选区域没有重叠区域。如果现有候选区域内的兴趣点不能满足用户的隐私需求,则应扩大候选区域,以搜索更多的兴趣点。如果候选区域的扩大导致部分候选区域重叠,则应避免在候选区域的重叠区域选择替代停留点。
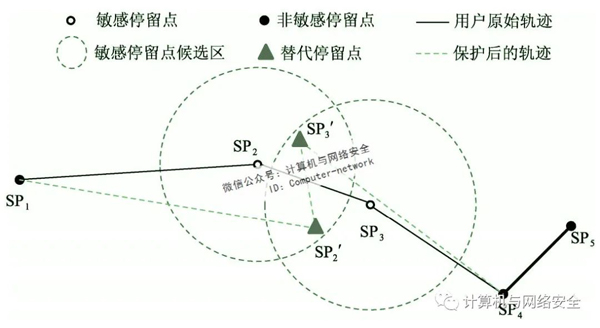
图6 候选区重叠导致轨迹相似度降低
方案中每个敏感停留点的候选区域都是以自身为中心,距离相邻停留点的较小值为直径的圆域。对于轨道上的第一个停留点,如果是敏感停留点,候选区的直径是它与下一个停留点之间的距离,如果轨道上的最后一个停留点是敏感停留点,则没有下一个相邻停留点,因此候选区的直径是它与上一个停留点之间的距离。
如图7所示,分析了用户的移动特征,从其轨迹中提取了5个停留点{SP1,SP2,SP3,SP4,SP5}。若其中{SP1,SP2,SP3}为了集合敏感停留点,虚线圆域是它们的候选区。SP1和SP5因为是边界点,只有一个相邻的停留点,所以它们的候选区半径分别是SP1到SP2、SP4到SP5距离的一半;和SP3存在前后相邻停留点SP2和SP4,因此,其候选区的半径是SP3到SP4距离的一半(因为SP3到SP4的距离小于SP2到SP3距离)。这样的候选区不会导致替代位置点过于偏离停留点本身,也可以避免候选区重叠导致轨迹相似度降低。
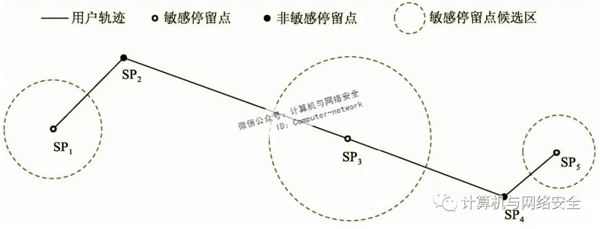
图7
(2)选择替代停留点
隐私保护程度l敏感区与敏感停留点最近但语义不同的其他兴趣点的数量至少是l个人。隐私保护的程度反映了敏感地区兴趣点的多样性。l值越大表示用户隐私需求越高。
在为每个敏感停留点构建一个合理的候选区后,下一项工作是为每个敏感停留点选择合适的兴趣点,并将其作为替代停留点,结合用户自定义的隐私需求。如果选择与敏感停留点语义相同或相似的兴趣点并将其作为替代停留点,恶意攻击者仍然可以从替代停留点的语义中推断出用户的敏感信息;在实际环境中,一些具有相同语义的兴趣点一般较远,可能导致选择的替代停留点偏离敏感停留点较远,需要重置的采样多,轨道完整性较低。
在这个计划中,敏感的停留点将被不同语义的兴趣点所取代。首先,以敏感停留点本身为中心,搜索取代停留点,并逐渐扩大搜索半径,直到不少于l语义和敏感停留点有不同的兴趣点;然后,根据距离敏感停留点的距离,从近到远对搜索到的兴趣点进行排序l作为替代停留点的候选集,包括敏感停留点和l兴趣点的最小矩形作为敏感区SA;最后,在敏感区域随机选择兴趣点,作为替代停留点。
在寻找替代停留点集时,通过每个新搜索的兴趣点,如果其语义不同于敏感停留点,则将其添加到候选集中。相反,忽略它,最终在敏感区域随机选择一个兴趣点,并将其作为替代停留点。敏感区域包含位置和语义多样性的兴趣点,这增加了攻击者推测真正敏感停留点的难度。同时,兴趣点选择的随机性也提高了真正敏感停留点的安全性。以最小包围矩形为敏感区域可以减少后需要重置的采样点数量,为提高轨迹的完整性奠定基础。
(3)重置局部采样点
敏感停留点SPi选取合适的替代位置后,需要为替代停留点SPif选择其中包含的停留核心点。同时,更换停留点后,可能会导致一些移动采样点在采样间隔内无法到达替代停留点,导致位置突变,攻击者很容易推断轨道段已更换。因此,为了提高发布后轨道的安全性,有必要重新选择轨道上的一些移动点。为了最大限度地保持轨道形状的一致性,尽量少修改原始轨道,局部采样点重置仅在敏感区域进行,重置时应充分考虑原始轨道上移动点的速度。同时,敏感区域中包含的采样点数量应与原来相同,以提高重置后轨道段的真实性。
局部采样点重置分为三部分:从敏感区入口到替代停留点之间的移动采样点重置、从替代停留点到敏感区出口之间的移动采样点重置。首先,局部采样点的重置,如图8所示,敏感区的第一个采样点是A,最后一个采样点是B;在A到SPi在原始轨迹段寻找点C,使C到SPi与C到SPif同样,距离差最小B到SPi在原始轨迹段上找到点D,使D到SPi与D到SPif距离差最小;同时,敏感停留点SPi覆盖范围作为替代停留点SPif覆盖范围;然后获得敏感区域移动点的速度值范围{Vmin,Vmax},分别在C到SPif和D到SPif段根据速度值和采样时间确定适当的新采样位置,并确保两个轨道段重置的采样点等于相应原轨道段的采样点。最后,在SPif覆盖范围内随机选取采样点,同样须保证采样位置点数不变。同时,为了提高轨迹抵抗攻击的能力,在选取任何新的采样点时需要检测其位置是否合理,采样点一般不应该位于湖泊中央等小概率的位置处。
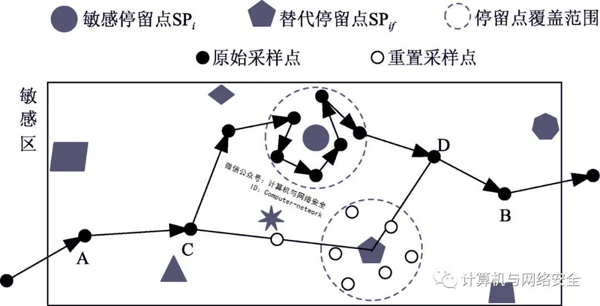
图8 局部采样点
查找到C、D在局部采样点重置过程中,两个采样点不需要重新选择整个敏感区域的采样位置点。这不仅减少了需要处理的采样位置点的数量,而且提高了轨迹的完整性。局部采样点重置后,用户轨迹的敏感隐私信息不再存在,可以直接发布和共享数据分析和研究。